Summer School Series: Lecture 5 by Rahul Sukthankar
This Lecture was presented by Rahul Sukthankar, a research scientist at Google Research and an Adjunct Professor at Carnegie Mellon University. It was titled Deep Learning in Computer Vision.
Popular Computer Vision tasks
Some popular tasks in the domain of computer vision include:
- Image Classification (assign to one class)
- Image Labelling/Object Recognition (multiple classes)
- Object Detection/Localization (predicts bounding box+label, works well for objects but not for fuzzy concepts)
- Semantic Segmentation (Pixel level dense labelling)
- Image Captioning (Description of image in text)
- Human Body Part Segmentation
- Human Pose Estimation (predicting 2D pose keypoints)
- Generating 3D Human Pose and Body Models from an image
- Depth Prediction from a single image (foreground and background semantic segmentation based on a heatmap)
- 3D Scene Understanding
- Autonomous navigation
While thinking about a particular problem statement:
- We need to take in specific considerations (such as semantic segmentation, classicaiton, object detection etc)
- What is the output? (binary yes/no, bounding box, label/pixel etc)
- How is the training data labelled? (Fully Supervised/Weakly or Cross-Modal/Self-supervised)
- Architecture: Usually a Convolutional Neural Network, but what is the final layer?
- What loss function do we use?
CMU Navlabs (30 years ago) built a self steering car only with an artificial neural network, in the pre-CNN era ( ALVINN: AN AUTONOMOUS LAND VEHICLE IN A NEURAL NETWORK)
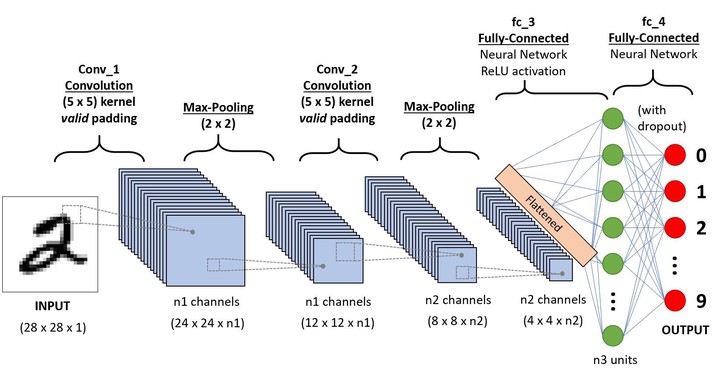
Convolutional Neural Networks
The structure of a convolutional neural network follows as input + conv, relu, pooling layers (hidden layers) + flatten, fully connected and softmax layers (for classification). Key concepts behind CNNs are:
- Local connectivity (not connected to every pixel, but just a few)
- Shared weights (translational invariance)
- Pooling (reducing dimensions, leads to local patch becoming bigger (filter size))
- Filter stride (cuts down weights, reduces computations)
- Multiple feature maps
It is essential to choose the right conv layer, pooling layer, activation function, loss function, optimization and regularization methods, etc.
Convolutions
- 2D vs 3D convolutions: 3D convolutions are used to capture patterns across 3 dimensions, for example Video Understanding and Medical Imaging.
- 1x1 convolution: weighed average across channel axis, feature pooling technique to reduce dimensions
- Other types of convolutions are dilated convolutions, regular vs depth wise separable convolutions, grouped convolutions (AlexNet uses it, it reduces computation)
Famous architectures
-
Inceptionv1 (2014):
![]()
Inception v1 -
ResNet:

Resnet uses skipped connections with residual blocks, the added paths help solve vanishing gradient problems and gives a shorter route for backpropagation

Object Detection in Images
- Object Classification: Task of identifying a picture is a dog
- Object Localization: Involves finding class labels as well as a bounding box to show where an object is located
- Object Detection: Localizing with box
- Semantic Segmentation: Dense pixel labelling
There are two ways to do detection:
- Sliding window approach: computationally expensive and unbalanced
- Selective search: guessing promising bounding boxes and selecting the best out of them
- RCNN did this when they extracted region proposals
- Fast RCNN did class labelling+ bounding box prediction at the same time (softmax+bounding box regression)
Bounding box evaluation is commonly done by the Intersection over Union Metric $$ \text{Intersection over Union} = \frac{\text{Area of Overlap}}{\text{Area of Union}}$$ (Ground truth bounding box and predicted bounding box)
Classic CNN vs Fully Convolutional Net
A classic CNN comprises of a conv+Fully Connected Layer, a fully convolutional layer contains convolutional blocks that help us retain the same number of weights no matter what the input image size is. An example of a fully convolutional net is the U-Net, that is used extensively for semantic segmentation.
Other applications of a fully convolutional net are : Residual Encoding Decoding, Dense Prediction, Superresolution, Colorization (self supervised)
Last-Layer Activation function and Loss Function Summary

Any differentiable function can be used as a loss function: even another neural net! (perceptual loss, GAN loss, differentiable renderer etc)
Rahul concluded this introduction lecture focused in Computer Vision using fully supervised deep learning, with key concepts on CNNs and their extensions and the importance of choosing the right loss function. It was a wonderful lecture with all the concepts beautifully explained.