|
Archana Swaminathan I'm a third year PhD student in the Department of Computer Science, at the University of Maryland in College Park, advised by Abhinav Shrivastava. My research lies at the intersection of computer vision and deep learning. I have interned at Amazon Science (Summer '24) and Bosch Research (Summer '21) Before starting my PhD, I had the pleasure of completing my undergraduate thesis in collaboration with V-SENSE, Trinity College Dublin, under the guidance of Prof. Aljosa Smolic. I graduated from BITS Pilani, India and double majored in Electrical Engineering and Mathematics. |
|
ResearchI specialize in 3D computer vision and scene understanding, developing algorithms that interpret complex, dynamic environments. My work focuses on decoding the physical properties of objects and their interactions in diverse 3D scenes, with a particular emphasis on applications in robotics. My research aims to bridge the gap between visual perception and practical implementation, pushing the boundaries of how machines interpret and interact with the world around them. |
|
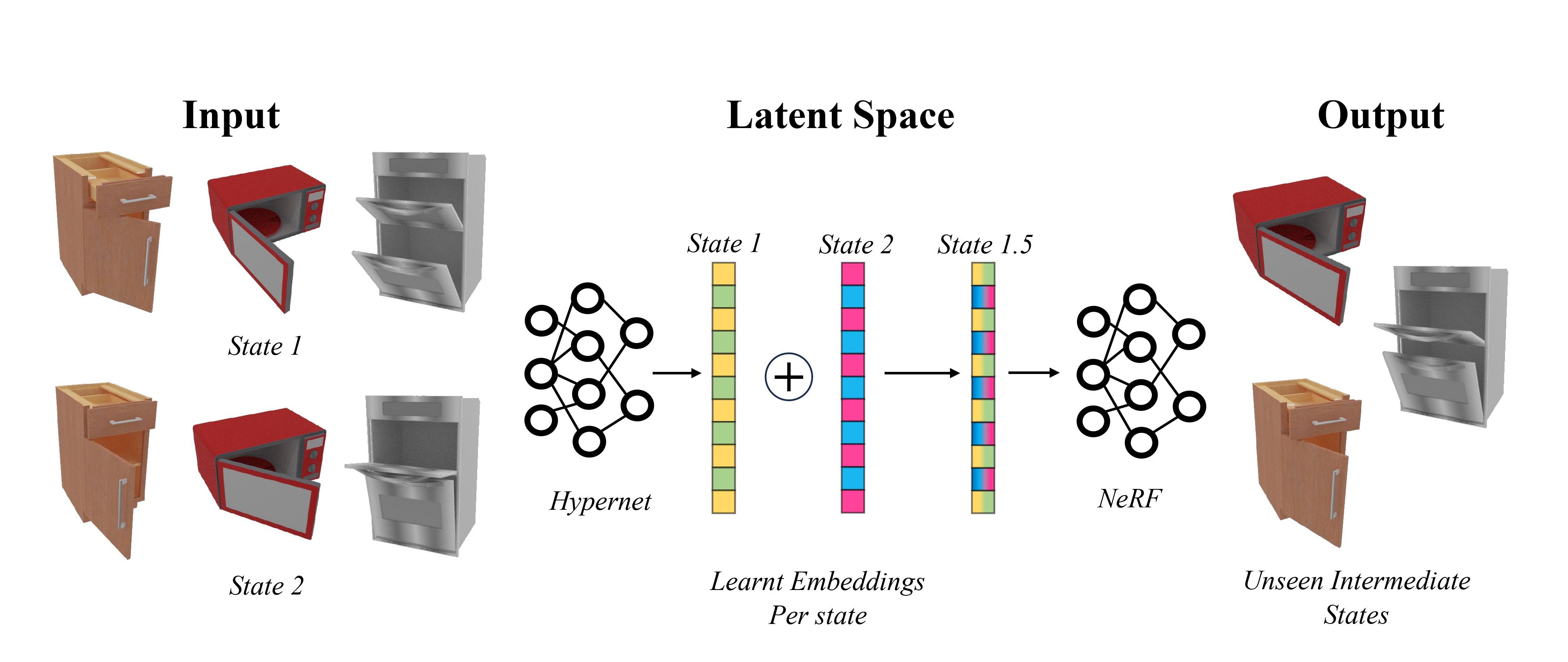
LEIA: Latent View-invariant Embeddings for Implicit 3D Articulation
Archana Swaminathan, Anubhav Gupta, Kamal Gupta, Shishira R Maiya, Vatsal Agarwal, Abhinav Shrivastava Proceedings of the European Conference on Computer Vision (ECCV), 2024 Modeling unseen 3D articulation states by interpolating across a learnable, view-invariant latent embedding space. Project / Paper |
|
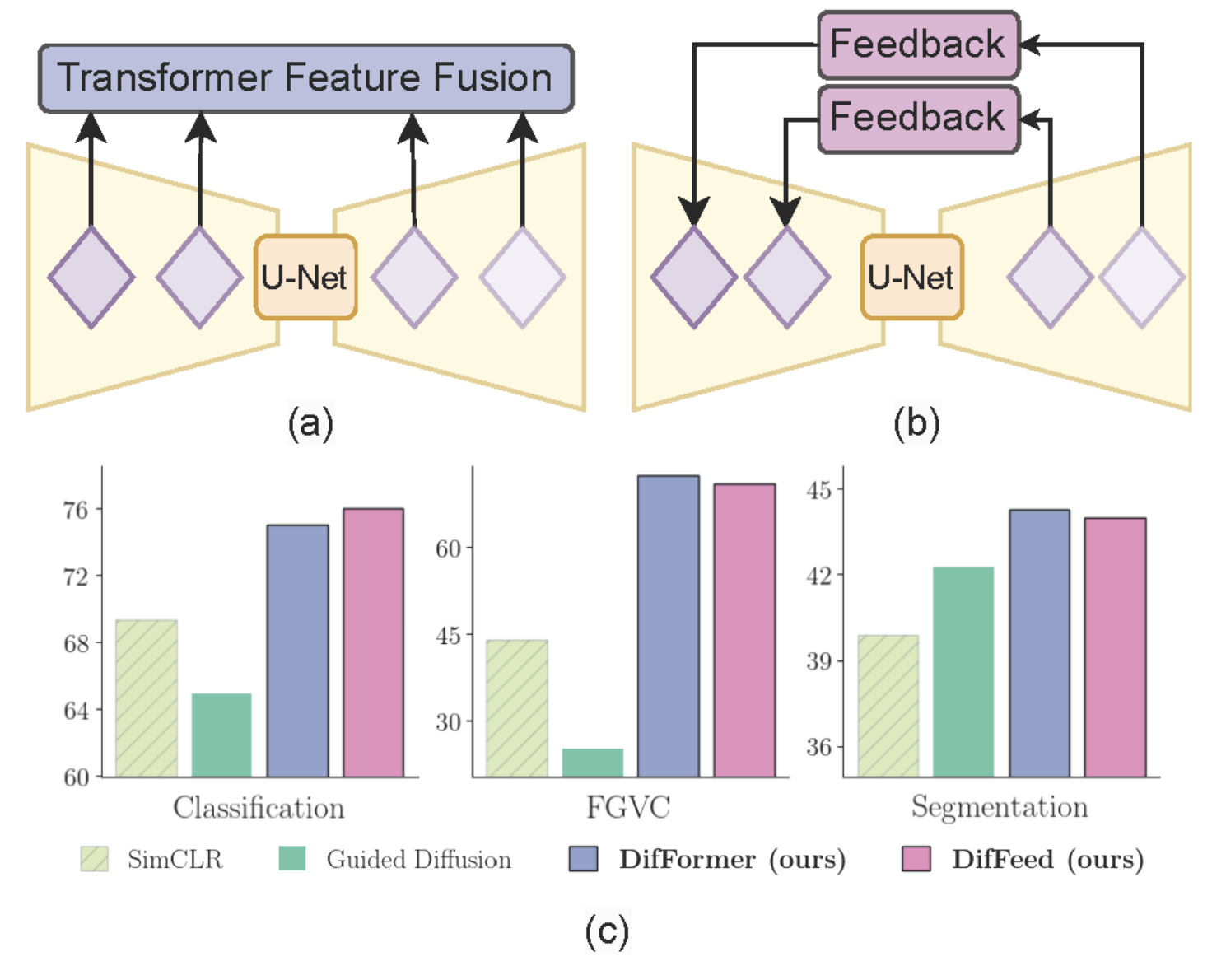
Do text-free diffusion models learn discriminative visual representations?
Soumik Mukhopadhyay*, Matthew Gwilliam*, Vatsal Agarwal, Namitha Padmanabhan, Archana Swaminathan, Tianyi Zhou, Abhinav Shrivastava Proceedings of the European Conference on Computer Vision (ECCV), 2024 Explore diffusion models as unified unsupervised image representation learning models for many recognition tasks. Propose DifFormer and DifFeed, novel mechanisms for fusing diffusion features for image classification. Project / Paper |
|
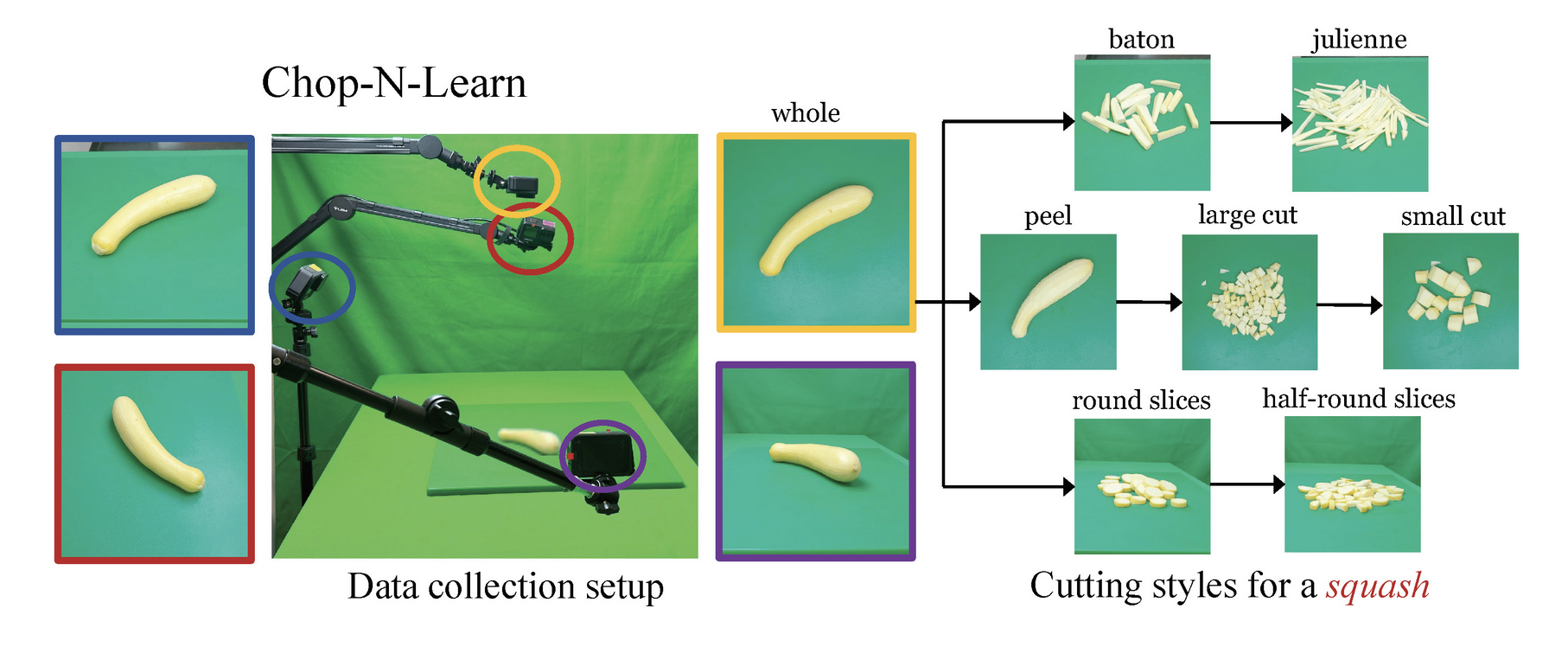
Chop & Learn: Recognizing and Generating Object-State Compositions
Nirat Saini*, Hanyu Wang*, Archana Swaminathan, Vinoj Jayasundara, Bo He, Kamal Gupta, Abhinav Shrivastava Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2023 Benchmark suite for fruits, vegetables and various cutting styles from multiple views. Compositional Image Generation supports generating unseen cutting styles of different objects. Project / Paper |
|
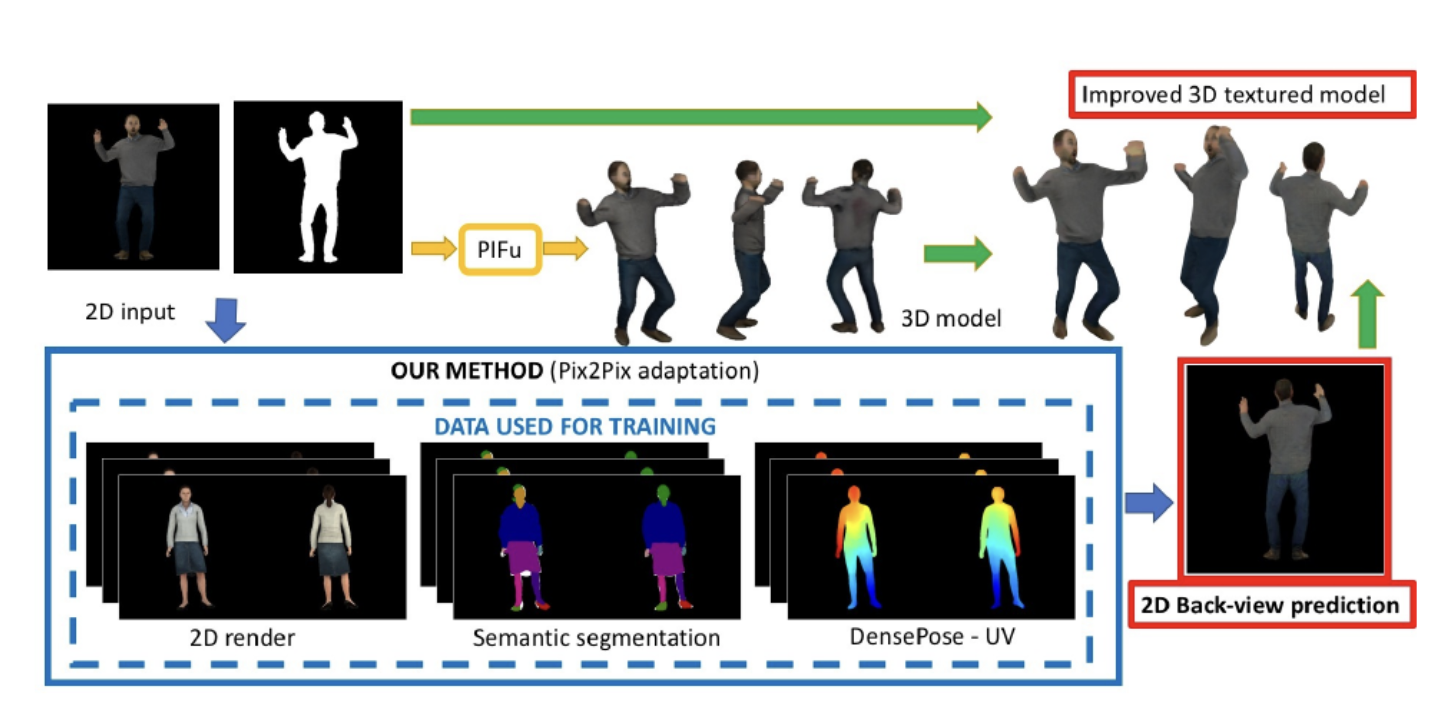
Texture improvement for human shape estimation from a single image
Jorge González Escribano, Susana Ruano Sainz, Archana Swaminathan, David Smith, Aljosa Smolic Proceedings of the 24th Irish Machine Vision and Image Processing conference (IMVIP), 2022 Novel way to predict the back view of the person by including semantic and positional information that outperforms the state-of-the-art techniques Paper |
|
Awesosme website credits go to this guy. |